Why use human data?
Human egocentric video captures rich manipulation demonstrations
without any robot hardware — anyone can collect
it, anywhere, anytime, no specialized workspace, no teleoperation rig,
no calibration.
More fundamentally, we see the corpus of human–world interaction
as one of the richest yet most under-explored data sources in
existence. If the long-term goal is robots that operate
effectively in the human world — helping people in
homes, kitchens, labs, and workshops — then the most direct and
natural source of supervision is people themselves
interacting with that exact world. Every minute of
egocentric video encodes how a body, a brain, and the physical
environment jointly solve a manipulation task. From this lens, human
video isn't merely a cheap substitute for robot data; it is a
superior and more efficient data
source for policy learning.
Why efficient robot learning from human egocentric videos?
The internet hosts an enormous amount of human video, and people often
assume "just train on YouTube" is a viable shortcut. But if you
actually look at what's inside these datasets, you find all kinds of
issues — most clips have no accurate action labels,
many suffer from uncompensated head motion (so the
camera shakes everywhere), and most are random everyday
activities with no specific task in mind.
Human data is super rich in quantity, but actually very poor
in quality.
We find it useful to think about an egocentric data pyramid,
analogous to the well-known robotics data pyramid:
-
Bottom (largest, lowest quality) —
passive videos like YouTube. Pixels-only, unlabeled, noisy. The
human in frame isn't collecting data for us. The biggest layer, but
also the hardest to use directly.
-
Middle — egocentric
demonstrations. Someone deliberately wears a camera and performs a
task, with hand poses tracked. Cleaner, has action labels, the
human is actively demonstrating. But still not good enough for
training a deployable policy.
-
Top (smallest, highest quality) —
teleop-grade human data: fully structured, interactive, with
accurate action labels, where the human interacts with the scene in
a way a robot could reproduce. This is what we want — but it
is very rare.
So the central question becomes: how do we squeeze every bit
of learning signal out of the small amount of teleop-grade human data
we can actually collect? That is exactly what HumanEgo is
built for — making the most of minutes, not hours or
days, of high-quality human egocentric data.
Why use Aria glasses?
Aria glasses are, today, the most mature and capable platform
for egocentric data collection. Two things set them apart
from anything else in the category: genuinely
lightweight, production-grade hardware that a
demonstrator can wear naturally for extended sessions in any
environment; and Meta's MPS pipeline, which delivers
calibrated SLAM, hand-pose estimation, and synchronized multi-stream
egocentric RGB out of the box — turnkey, no per-session
calibration.
The precision of these signals is what really matters: our
experiments show that the accuracy of the upstream SLAM and
hand-tracking signal directly bounds downstream policy performance.
Noisy poses propagate into the action loss and the learned
representation; the clean, drift-free trajectories from Aria are
exactly what enable HumanEgo to converge on minutes of data. No other
consumer egocentric device today delivers this level of out-of-the-box
accuracy.
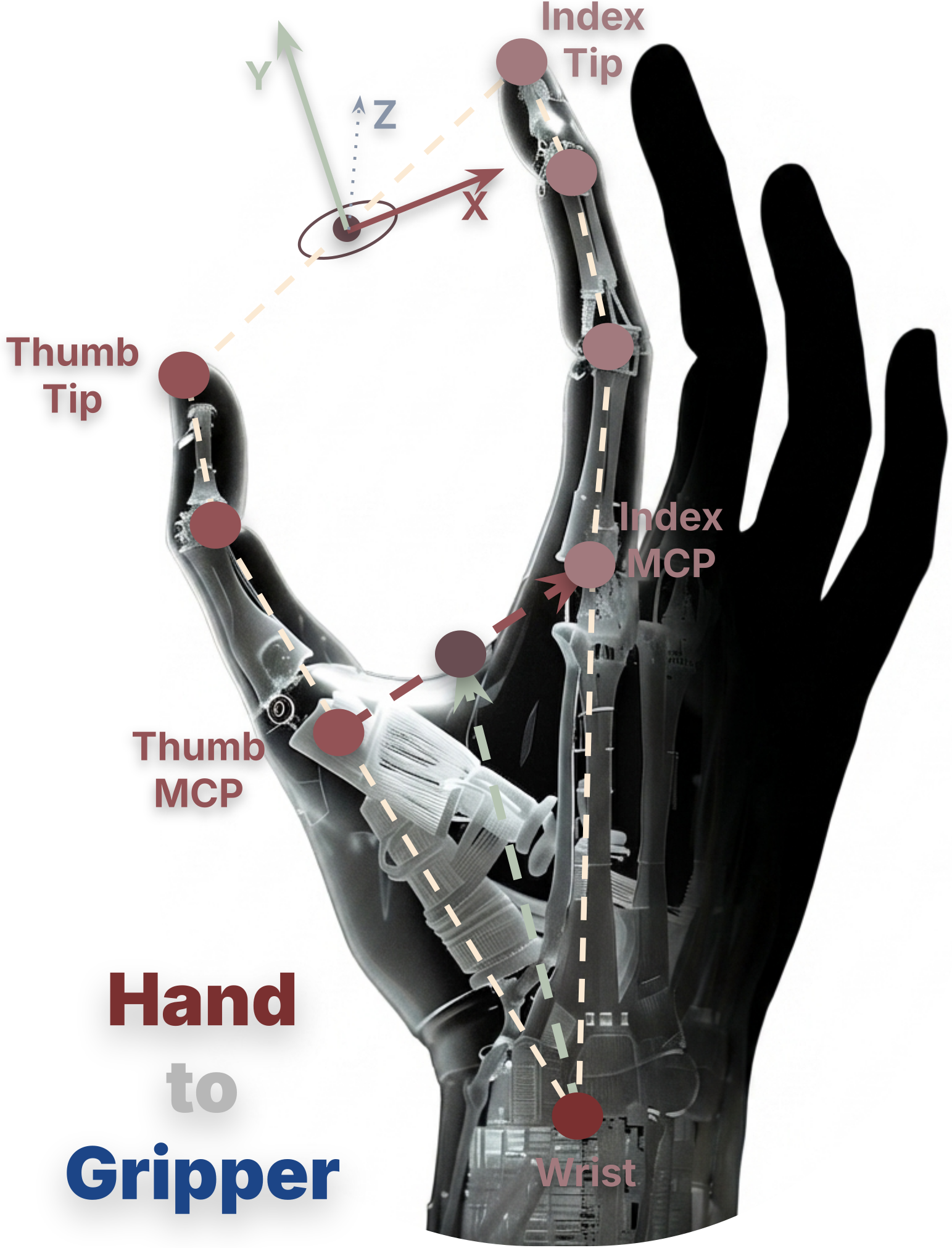
Why are Interaction-Centric Tokens (ICTs) so powerful — and why doesn't visual fidelity matter as much?
ICTs encode each entity (hand and object) by its 6-DoF pose
relative to other task entities, not relative to the camera
or a fixed world frame. This makes the representation invariant to
embodiment, viewpoint, and environment — the same ICT tokens
describe the same skill whether the demonstrator is a human or a
robot, whether the camera is a RealSense or a ZED, whether the table
is tall or short. The policy learns once and transfers everywhere.
As for why visual fidelity matters less than people expect: vision is
obviously central to how humans experience the world —
but for most manipulation tasks, it isn't strictly required. Imagine
glancing at a table, closing your eyes, and then putting a flower
into a vase. You can still do it. Once a brief look gives you a
coarse spatial map, the rest of the task runs on
spatial memory, proprioception, touch, and the geometric
interaction between hand and object — not on continued
visual confirmation. Manipulation is fundamentally a
spatial-and-interaction problem; vision is just one of several inputs
that surfaces that structure.
Inspired by this, we designed ICT to make spatial observation and
hand–object interaction the first-class citizens of
the policy. The result is an elegantly compact representation that is
unified (every entity, hand or object, lives in the
same token format), easy to implement (off-the-shelf
pose estimators are enough), variable-length (works
whether the scene has one object or many), and
embodiment-invariant (the same token whether the
body is a human or a robot).
That mix of simple-but-right choices is precisely why HumanEgo
generalizes so widely. Empirically, adding ICTs to raw human RGB
jumps Water Flowers success from 7.5% to 85% — a
+77.5 pp gap that no amount of visual preprocessing
can close. We believe ICT is a simple yet critical
representation that should reach well beyond this paper — a
general-purpose spatial encoding for any embodied agent that needs to
reason about object interactions.
Why do dense auxiliary objectives work?
Think about what supervision the policy actually receives from a
single demonstration: at each timestep, the model sees one image and
one set of ICTs, and is asked to regress one action chunk. That's a
single, narrow learning signal — action in, action out.
With only minutes of data, that's just not a lot of bits
flowing through the gradient.
But each demonstration secretly carries far more information
than the action label alone. Where does the object end up?
Where do the hand and object project on the image over time? How does
the scene's internal state evolve? All of that signal is sitting
for free inside every trajectory — we just aren't
asking the model to predict it.
So we add three auxiliary objectives, all sharing the same encoder as
the flow-matching head: Object Motion (forecast each
manipulated object's future 6-DoF trajectory),
2D Trace (forecast the image-plane projection of
hand and object — the path your eyes would follow watching the
video), and Latent Consistency (forecast the
encoder's own internal representation K steps ahead).
Zoom out, and all three are asking the model to do the
same thing: forecast how the scene evolves over the
next few steps, in three complementary spaces — 3D
physical, 2D visual, and the encoder's own latent state. Together,
this turns the encoder into a lightweight world model of
hand–object interaction, sitting right inside the
policy for free.
Because all three losses share the same encoder, the encoder is
forced to learn the causal structure of manipulation
— not just what action comes next, but why:
how the scene will respond. And critically, none of these targets
cost us anything to obtain — they are computed automatically
from the same perception pipeline that gave us the ICTs.
No extra annotation, no extra data — just more
questions asked of the same demonstration.
Why is human data better and more efficient than robot data?
First, an important caveat: when we say human data, we mean
carefully designed human-egocentric data —
captured with intent, the manipulation task clearly in mind, the
camera stable on the head, the hand pose tracked. Comparing random
YouTube footage against carefully designed teleop data is
apples-to-oranges. What we are comparing here is carefully
designed human data against carefully designed teleop
data.
Higher-quality data is intrinsically easier for humans to
produce. A demonstrator naturally generates motion that is
smooth, dexterous, fast, and physically plausible:
they cover a much larger workspace than any single robot, switch
grip strategies on the fly, and adapt in milliseconds — without
any active control loop or training. Teleoperation, by contrast, is
fundamentally a lossy remote-control problem:
smoothness, speed, and dexterity all bottleneck on the operator's
skill at piloting the robot. Top-tier teleop exists, but it is
rare and expensive; everyday teleop produces choppy,
slow, or unrepresentative trajectories that the policy then has to
learn from.
Human data generalizes more naturally across embodiments
and environments. Given the right processing pipeline
(ours uses an entity-relative ICT representation), human data is
inherently more transferable — it isn't
bound to any particular robot's kinematic configuration, gripper,
base height, or camera mount, so the same dataset can serve many
target embodiments. Teleop data is the opposite: it is born inside
one specific robot's body, so a new arm, a new gripper, or even a
new camera mount typically means re-collecting the entire
dataset.
You already have ICTs — why not just use TAMP (Task-and-Motion Planning)?
You certainly could — TAMP is a perfectly
legitimate way to solve a manipulation task. But the two approaches
are nowhere near equal in cost. A learned policy
comes automatically out of a handful of
demonstrations: you perform the skill, and the network recovers the
controller. TAMP has to be hand-built for every task
— a symbolic domain, action operators, goal predicates, and a
motion-planning stack, each assembled and tuned by an expert. What
HumanEgo extracts from minutes of data, TAMP extracts from
days of engineering.
Learning also generalizes where hand-engineered planning does
not. Swap the object, rearrange the clutter, or move to a new
scene, and a TAMP pipeline generally has to be re-modeled and
re-tuned — new geometry, new predicates, new
constraints. A HumanEgo policy instead learns the general
way to accomplish the task rather than a script for one instance
of it, so novel objects and novel environments are handled as a
matter of course, not as the next engineering ticket.
One might object that ICTs already make the scene
structured — haven't we just smuggled TAMP's
modeling burden back in? No. Constructing the ICT
representation adds no new inputs: it falls out of the
same off-the-shelf pose estimation we already run —
just the 6-DoF poses of hands and objects, nothing more. TAMP's
required priors run far past that: object models,
symbolic predicates, operator definitions, explicit goal states,
collision geometry. ICTs buy structure essentially for free; TAMP
pays for it in hand-specified prior knowledge.
So while TAMP remains a valid option, in the regime we actually care
about — many tasks, many objects, many environments, only
minutes of data — HumanEgo's learning-based route solves the
problem more efficiently, more generally, and with far less
hand-engineering. The result is a controller that is
fast to obtain, robust to run, and general by
construction — without ever committing to a
task-specific planning pipeline.
Have you tried dexterous hands?
Not yet on a real dexterous hand — every result
in the paper maps to a standard parallel-jaw gripper.
But supporting a multi-fingered hand is a natural extension, not a
redesign. Our pipeline already tracks the full
21-keypoint hand pose for every demonstration; the gripper
mapping simply collapses that rich hand configuration down to a single
open/close degree of freedom. Retargeting those same
keypoints onto a dexterous hand instead is
feasible in principle — the main change is that
the policy's action head now outputs a
higher-dimensional finger configuration rather than
one scalar.
How well would it work? For the pick-and-place regime
HumanEgo targets, we'd expect it to transfer well
— grasping and transporting an object mostly needs the hand to
reach a good global pose and close, which keypoint
retargeting captures. For genuinely fine, finger-level
manipulation — in-hand reorientation, dexterous
regrasping, precise individual-finger control — we're more
cautious. Those skills demand tight per-finger coordination (and often
tactile feedback) that is far less forgiving of retargeting error and
much harder to learn from minutes of data. So dexterous hands
are squarely on our roadmap: we expect them to work
for coarse manipulation well before they work for the truly delicate
stuff.
Why not use Aria Gen 2 — and how can I get access to Aria?
Timing, mostly. We started this project in
November 2025, before Aria Gen 2 was available
— so Gen 1 was simply the best tool on hand, and every result in
the paper comes from it. Aria Gen 2 ships
substantially more capable hardware, and we fully
expect it to be an even better platform for this line of work
— trying HumanEgo on Gen 2 is on our near-term
list. Encouragingly, nothing in our method is tied to a
particular Aria generation: the pipeline consumes calibrated SLAM and
hand poses, which both generations provide, so we expect the move to
Gen 2 to be a straightforward upgrade rather than a
re-engineering effort.
Getting access to Aria. The glasses are distributed
through Meta's Project Aria research program. You can
apply for the Aria Research Kit and find the current eligibility and
application details at
projectaria.com.
Does third-person (exocentric) video data also work?
Yes — and it may even work better. Egocentric
capture is what we built HumanEgo around, but nothing about the method
requires a first-person view. We tried it directly: we recorded human
demonstrations with a fixed third-person ZED camera,
ran them through the exact same pipeline, and the learned
policy came out just as strong.
If anything, the exocentric setting is simpler. A
head-mounted camera moves with the demonstrator, so egocentric data
needs a SLAM step to recover that camera motion
before anything else. A fixed third-person camera doesn't move
— so that whole step disappears, and you only
need hand (and object) tracking to build the ICTs.
Everything downstream — the ICT representation, the
architecture, the training objectives — stays
identical. Dropping SLAM also removes one of the
biggest sources of upstream error, which is plausibly why the
third-person policies look at least as good. In short, HumanEgo
transfers to exocentric video almost for free.
Give it a try.
Can I use other hardware — Meta Quest, Apple Vision Pro, iPhone, RealSense, etc.?
Absolutely — in principle, yes. HumanEgo
doesn't depend on Aria specifically; it depends on
three signals: raw RGB, the
camera's motion (head SLAM, for a worn or moving
device), and hand tracking. Give the pipeline those,
and everything else is unchanged — it builds the ICTs, cleans
the image, and trains the policy to output actions, exactly as in the
paper. Some devices provide these signals natively (a headset's
onboard inside-out tracking and hand tracking); for others you recover
them with off-the-shelf, open-source models. Either
way, a Quest, a Vision Pro, an iPhone, or a RealSense can all feed the
same pipeline.
The one real caveat is precision. The accuracy of the
upstream SLAM and hand-tracking signal directly bounds
downstream policy performance — and that is exactly where Aria
shines, delivering clean, drift-free, calibrated signals out of the
box. Other devices can provide the same kinds of signals, but
often at lower accuracy, so the resulting policy may
not reach the same quality. Crucially, that's a matter of
signal quality, not method compatibility — and as
off-the-shelf trackers keep improving, the gap keeps shrinking. Well
worth a try.
What role does the image actually play — does it matter much?
Less than you might expect. We worked hard to squeeze
performance out of the raw image — we tried
arm inpainting (masking out the demonstrator's arm to
close the human–robot appearance gap) and
keypoint rendering (drawing the tracked hand/object
keypoints back onto the frame), among other things. None of it moved
the needle much. What finally made the policy work was adding the
ICTs — the geometric, interaction-centric
tokens — not better pixels. That outcome
validated the thesis behind HumanEgo: for
manipulation, visual fidelity carries far less of the load than people
assume, much as a human can glance at a scene once and then finish the
task largely from spatial memory.
This is not a claim that vision is useless.
Two things keep it firmly in the loop. First, with the ICTs held
fixed, a policy that also sees the image still
beats one that doesn't — the pixels contribute
real, if modest, signal on top of the geometry. Second, and more
fundamentally, building the ICTs requires a look in the first
place: that initial glance — localizing the hands and
objects in the scene — is itself a visual step. Vision is doing
genuine work here; it is simply not the dominant input it is so often
assumed to be.
And we don't think this is the last word on vision — quite the
opposite. How best to use visual input deserves
serious study. People clearly rely on continuous vision for
dynamic and high-precision manipulation — the
very tasks that sit outside HumanEgo's current reach — and it is
only within our task setting that vision turns out to matter
less than expected. We'd be glad if this finding provokes more
thinking and research on exactly when, and how, vision should drive a
manipulation policy.
Does this pipeline scale up?
Yes — and we think that's where it gets exciting.
Everything in the paper runs on minutes of data; the natural
next axis is simply more of it. For
longer-horizon, harder tasks, we fully expect more
data to push results well past what we report today. And the pieces
are built to scale: the processing pipeline, the
ICT construction, and the auxiliary training
objectives are all automatic and data-driven — nothing
about them caps out at small scale, so they should keep paying off as
the dataset grows. We'd love for people to push on this.
A more personal view, and an honest one: I'm less sure that
scaling data alone will crack the hardest cases. For
genuinely fine, finger-level dexterous manipulation,
I suspect the representation and architecture themselves will
need to evolve — not just the data budget. That remains
very much an open question, and it is one I'm
actively researching. If you're thinking about the same problem, I'd
genuinely welcome the conversation.
What are the limitations of HumanEgo?
HumanEgo is built for coarse, large-motion
(“broad-strokes”) manipulation — the regime
where our ICT representation and architecture genuinely shine. It is
not, today, the right tool for everything. In
particular, it struggles with deformable objects,
very fine or precise manipulation, highly
dynamic motions, and in-hand manipulation
— and it carries a hard precision ceiling of roughly
1 cm. If a task needs sub-centimeter accuracy or tight
reactive control, HumanEgo will not reliably solve it.
These limits follow directly from how the system is built. Our
object tracking leans on off-the-shelf foundation
models for pose estimation, and their error
accumulates — that is what sets the ~1 cm
floor and rules out high-precision insertion. The ICT
representation describes each entity by a rigid 6-DoF pose,
so a deformable object — cloth, rope, a soft
bag — has no well-defined pose to encode, and ICT construction
simply fails. And because the policy acts on a coarse spatial snapshot
rather than tight, high-frequency visual feedback, fast
dynamic tasks and in-hand reorientation
— which demand continuous reaction and fine per-finger contact
— sit outside what it can currently do.
There is an intuition we like that draws the boundary cleanly. Recall
the idea behind ICTs: glance at a scene once, close your eyes, and you
can still complete many manipulation tasks from spatial memory alone.
HumanEgo can do almost exactly the set of tasks you could do
with your eyes closed after a single glance —
pick-and-place, pouring water, and the like. The tasks you
couldn't do blind — inserting a USB, threading a
needle, reacting to a moving object — are precisely the ones
HumanEgo can't do either. That is not a coincidence; it is the same
principle that makes ICTs work, seen from the other side.
Encouragingly, each boundary is tied to a specific, improvable
component — sharper trackers raise the precision ceiling, and
richer state or touch sensing could open up deformable and in-hand
tasks — so we expect this frontier to keep moving.
 HumanEgo
Zero-Shot Robot Learning
from Minutes of Human Egocentric Videos
HumanEgo
Zero-Shot Robot Learning
from Minutes of Human Egocentric Videos